応用情報技術者試験 過去問 2015年(平成27年) 春期 午後 問3
データ圧縮の前処理として用いられるBlock-sorting
Block-sortingは,文字列に対する可逆変換の一種である。変換後の文字列は,変換前の文字列と比較して同じ文字が多く続く傾向があるので,その後に行う圧縮処理において圧縮率を向上させることができる。
Block-sortingは,変換処理と復元処理の二つの処理で構成される。変換処理は,入力文字列を受け取って,変換結果の文字列と,入力文字列がソート後のブロックで何行目にあるか(以下,入力文字列の行番号という)を出力する。一方,復元処理は,変換結果の文字列と入力文字列の行番号を受け取って入力文字列を出力する。
データ圧縮におけるBlock-sortingの使用方法を図1に示す。

Block-sortingの変換処理
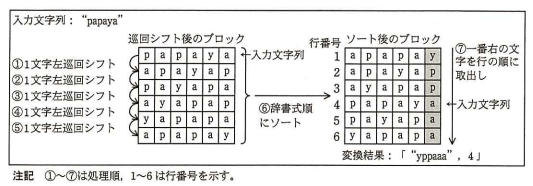
例として"papaya"を入力文字列としたときの変換処理を図2に示す。図2では,入力文字列を1文字左に巡回シフトすること(①)で文字列"apayap"となる。さらに,もう1文字左に巡回シフトすること(②)で文字列"payapa"となる。同様に1文字ずつ左に巡回シフトした(③~⑤)結果の文字列を縦に並べて正方形のブロック(巡回シフト後のブロック)を作成する。
次に,このブロックを行単位で辞書式順にソートし(⑥),ソート後のブロックを得る。ソート後のブロックの各行の文字列から一番右の文字を行の順に取り出して並べた文字列と,ソート後のブロックにおいて入力文字列に一致する行の行番号を変換結果とする(⑦)。
Block-sortingの復元処理
図2の変換結果「"yppaaa",4」を復元する手順を表1に示す。
| 手順 | 処理 | 内容 |
|---|---|---|
| 1 | 変換結果の文字列に対して,各文字に1から順に添字を付ける。 | "yppaaa" → "y(1),p(2),p(3),a(4),a(5),a(6)" |
| 2 | 文字をソートする。同じ文字の場合は添字の順に並べる。 | "y(1),p(2),p(3),a(4),a(5),a(6)" → "a(4),a(5),a(6),p(2),p(3),y(1)" |
| 3 | 手順2でソートした文字を次の手順で並べる。 ・変換結果の行番号"4"から,ソート後の文字列"a(4),a(5),a(6),p(2),p(3),y(1)"の4番目の要素"p(2)"を取り出して並べる。 ・"p(2)"の添字が2であることから,2番目の要素"a(5)"を取り出して並べる。 ・"a(5)"の添字が5であることから5番目の要素の"p(3)"を取り出して並べる。以降,並べた要素の個数が変換結果の文字列の長さと同じになるまで,要素を取り出して並べることを繰り返す。 |
→ "p(2)" → "p(2),a(5)" → "p(2),a(5),p(3)" → "p(2),a(5),p(3),a(6)" → "p(2),a(5),p(3),a(6),y(1)" → "p(2),a(5),p(3),a(6),y(1),a(4)" |
| 4 | 手順3の結果から添字を取り除く。 | "p(2),a(5),p(3),a(6),y(1),a(4)" → "papaya" |
Block-sortingの実装
Block-sortingのプログラムを作成するために使用する配列,関数及び変数を,表2に示す。
変換処理関数encode
変換処理を実装した関数encodeのプログラムを図3に示す。
function encode(InputString)
rString ← InputString
for( i を ア から イ まで1ずつ増やす )
EncodeArray[i] ← rString
rString ← rotation(rString)
endfor
sort1(EncodeArray)
BlockSortString を空文字列に初期化する
for( k を ア から イ まで1ずつ増やす )
BlockSortStringの末尾に EncodeArray[k]の末尾の1文字を追加する
if( ウ )
Line ← k
endif
endfor
endfunction
復元処理関数decode
復元処理を実装した関数decodeのプログラムを図4に示す。
function decode(BlockSortString, Line)
for( i を1から BlockSortStringの長さまで1ずつ増やす )
DecodeArray[1][i] ← BlockSortStringの i 文字目
DecodeArray[2][i] ← i
endfor
sort2(DecodeArray)
OutputString を空文字列に初期化する
OutputStringの末尾に エ に格納されている1文字を追加する
n ← オ
while( カ )
OutputStringの末尾に DecodeArray[1][n]に格納されている1文字を追加する ← (α)
n ← DecodeArray[2][n]
endwhile
endfunction
関数sort2(Array[][])の実装
関数decodeの処理時間は,使用する関数sort2(Array[][])の計算量に大きく依存する。処理時間を短くするためには,sort2(Array[][])の内部で計算量が少ないソートのアルゴリズムを使用して実装する必要がある。
処理時間の違いを確認するために複数のソートアルゴリズムを使用して関数sort2(Array[][])を実装したところ,Array[1]の要素をキーにしてクイックソート(不安定なソート)を使用した場合には復元処理の結果が入力文字列と一致しなかった。
この場合,sort2(Array[][])が表1の手順2を正しく実装できていないので,(β)ソートアルゴリズム,ソートキーのいずれかを見直す必要がある。