応用情報技術者試験 過去問 2010年(平成22年) 春期 午後 問2
アプリケーションで使用するデータ構造とアルゴリズム
PCのデスクトップ上の好きな位置に付箋を配置できるアプリケーションの実行イメージを図1に,付箋1枚のデータイメージを図2に示す。
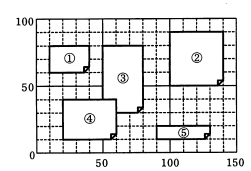
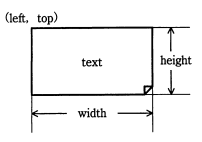
複数の付箋データを管理する方法として,配列と双方向リスト(以下,リストという)のいずれがよいかを検討することにした。そこで,図1の付箋③のように最奥の付箋の背後にある付箋を一番手前に移動するアルゴリズムを,配列とリストそれぞれで実装して比較検討する。使用する構造体,配列,定数,変数及び関数を表に示す。
また,図1の付箋①~⑤を順番に,配列及びリストにそれぞれ格納した際のイメージを図3,4に示す。
なお,配列及びリストの末尾に近い付箋データほど,デスクトップ上の手前に表示される。
| 名称 | 種類 | 内容 |
|---|---|---|
| Memo | 構造体 | 一つの付箋のデータ構造。次の値を管理する構造体である。 id…付箋の一意なID,text…付箋のメモ内容 left,top…付箋の左端,上端の位置 width,height…付箋の幅,高さ |
| MEMO_MAX_SIZE | 定数 | デスクトップに配置できる付箋の最大数。 |
| MemoArray | 配列 | 構造体Memoを要素(付箋データ)とする。要素数がMEMO_MAX_SIZE の配列。配列の各要素は,MemoArray[i]と表記する(iは配列の添字)。 配列の添字は0から始まるものとする。 |
| memoArrayCount | 変数 | 配列MemoArrayに格納されている付箋データの個数。 |
| moveForeArray(id) | 関数 | 付箋IDがidである付箋データを配列MemoArrayの末尾へ移動する。 |
| findArrayIndex(id) | 関数 | 配列MemoArray中で付箋IDがidである付箋データの添字を返す。 |
| MemoListNode | 構造体 | 付箋データを表すノードのデータ構造。これがリストを構成する。次の 値を管理する構造体である。 data…付箋データ(構造体Memo) prevNode,nextNode…前,次ノードへの参照。リストの先頭ノードの prevNodeと末尾ノードのnextNodeはnullである。 |
| headNode | 変数 | リストの先頭ノードへの参照。初期値はnullである。 |
| tailNode | 変数 | リストの末尾ノードへの参照。初期値はnullである。 |
| moveForeList(id) | 関数 | 付箋IDがidである付箋データのノードをリストの末尾へ移動する。 |
| findListNode(id) | 関数 | 付箋IDがidである付箋データが格納されているリスト中のノードへの参 照を返す。 |

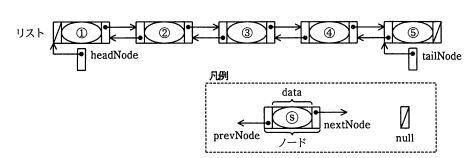
構造体の要素は"."を使った表記で表す。"."の左には,構造体を表す変数又は構造体を参照する変数を書く。"."の右には,要素の名前を書く。配列の場合,図3の付箋⑤のメモ内容はMemoArray[4].text,また,リストの場合,図4の付箋②のIDはheadNode.nextNode.data.idと表記できる。
関数moveForeArray
関数moveForeArrayの処理手順を次の(1)~(4)に,そのプログラムを図5に示す。
- 配列中の付箋IDがidである付箋データの添字を取得する。
- 配列中の(1)で取得した位置の付箋データを一時変数へ退避する。
- 配列中の(1)で取得した位置の次から配列の最後の付箋データがある位置までの付箋データを一つずつ前へずらす。
- 配列中の最後の付箋データがあった位置へ(2)で退避した付箋データを代入する。
function moveForeArray(id)
index ← findArrayIndex(id)
tempMemo ← ア
for(i を index+1 から イ まで1ずつ増やす)
MemoArray[i-1] ← MemoArray[i]
endfor
MemoArray[イ] ← tempMemo
endfunction
関数moveForeList
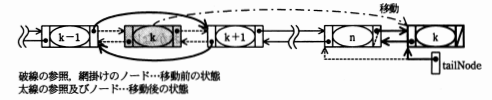
関数moveForeListの処理手順を次の(1)~(4)に,処理手順中の(3)(i)及び(4)の操作を図6に示す。また,関数moveForeListのプログラムを図7に示す。
- リストから,付箋IDがidである付箋データをもつノードへの参照を取得する。
- で取得したノード(ノードk)が末尾ノードの場合,処理を終了する。
- ノードkが先頭ノードの場合は(i)を,そうでない場合は(ii)を実行する。ここで,ノードkの次ノードをノードk+1,前ノードをノードk-1と呼ぶ。
- リストの先頭ノードへの参照をノードk+1への参照に変更し,ノードk+1中の前ノードへの参照をnullに変更する。
- ノードk-1中の次ノードへの参照をノードk+1への参照に変更し,ノードk+1中の前ノードへの参照をノードk-1への参照に変更する。
- リストの末尾ノード(ノードn)中の次ノードへの参照をノードkへの参照に,ノードk中の前ノードへの参照をノードnへの参照に変更する。ノードk中の次ノードへの参照をnullに,リストの末尾ノードへの参照(tailNode)をノードkへの参照に変更する。
function moveForeList(id)
node ← findListNode(id)
if (node.nextNode と null が等しい)
// 末尾ノードの場合
return
endif
if (node.prevNode と null が等しい)
// 先頭ノードの場合
headNode ← node.nextNode
node.nextNode.prevNode ← null
else
// 先頭ノード以外の場合
node.prevNode.nextNode ← node.nextNode
ウ
endif
tailNode.nextNode ← node
エ
node.nextNode ← null
tailNode ← node
endfunction
二つのアルゴリズム
まず,時間計算量について考える。配列の場合,末尾へ移動する要素より後のすべての要素をずらす必要が生じる。この処理の計算量はオである。リストの場合,末尾へ移動する付箋データの位置にかかわらず,少数の参照の変更だけでデータ同士の相対的な位置関係を簡単に変えられる。この処理の計算量はカである。
次に,必要な領域の大きさについて考える。付箋データ1個当たりの領域の必要量は,配列の方が小さい。リストは参照を入れる場所を余分に必要とする。しかし,全体で必要とする領域は,配列の場合,キしておかなければならない。リストの場合,配置されている付箋データの個数分だけ領域を確保すればよい。